03/06/2008: Cuebee has a sister project Exparql, that focus on visualizing and exploring results from SPARQL queries.
20/02/2008: Cuebee will be extended as part of an NIH grant.
11/02/2007: Cuebee is being used to build TcruziKB to query data about the important parasite Trypanosoma cruzi.
10/31/2007: Pre-alpha version released. Major refactoring of the code for distribution is ongoing.
Abstract:
The objective of Cuebee is being completely immersed in SPARQL (but shielding the user from the underlying implementation choices).
In Cuebee we generate SPARQL queries by SPARQL querying the target endpoint.
As the user types in an input box, we suggest existing terms from the target endpoint.
When the user selects a term, we look for properties of that term, values for that property, and so on until the user has built a SPARQL query reflecting his/her information need.
When the user clicks "Query" we send the queries to SPARQL endpoints, fetch results and display the results by reading in SPARQL JSON in applicable visualization widgets.
We are gradually developing both native SPARQL visualization widgets and SPARQL Protocol-compliant wrappers to existing visualization tools.
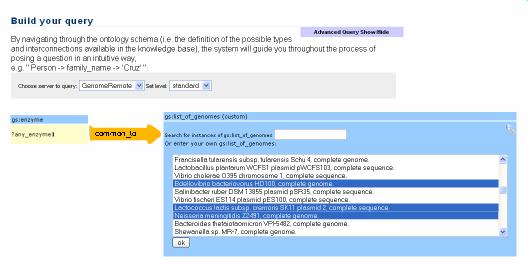
Cuebee is a flexible, extensible application for querying the semantic web. It provides a friendly interface to guide users through the process of formulating complex queries. No technical knowledge of query languages or the semantic web is required.
The query formulation process starts with a "query suggestion", where the user looks for a term to start building his or her query.
A term can be a variable, instance or class in the ontology.
Then, by reading the ontology schema (or an inferred structured of the dataset),
the system retrieves all possible properties that apply to the selected "root" term, and present them in a list for the user to choose.
When a property is chosen, another background query to the schema retrieves the possible classes in the range of that property.
The process continues iteratively, until the intended query is achieved.
The system then formulates a SPARQL query and submits to the SPARQL server.
Results are obtained in SPARQL JSON and the interfaces for visualization of results are notified.
Cuebee's architecture has four components:
Query Builder: interface that guides the user on specifying a query based on ontology schemas
Results Explorer Widgets: we provide a reference implementation of a widget that can subscribe to Cuebee to be notified with results to be displayed.
Other developers can easily extend Cuebee to display results in any way they want.
Controller: core component that takes care of executing queries and notifying observer widgets
SPARQL Server: a web ontology server implementation that is able to speak SPARQL Protocol and implements additional helper functions for performance
Cuebee supports any server that implements the SPARQL Protocol for RDF
My queries are slow, I'm using RDF level querying, any thoughts?
Cuebee is agnostic to server implementation. The idea is to use the SPARQL Protocol to access information in RDF (with or without schema description in RDFS), regardless of where they are stored (in memory, disk, RDBMS, etc.) If your server provides schema description in RDFS, you should query it in RDFS level. If the server doesn't offer that convenience, then there is no way for Cuebee to know what types of things are in your data store, unless we do something like this:
SELECT ?class WHERE { [] rdf:type ?class }
I do not understand why we need to iterate over all triples just to get the names of all classes
We don't need to do iterate over all triples if the server offers us a way to get the same information using another method. For example, if the server has a schema description, we can send this query:
SELECT ?class WHERE { ?class rdf:type rdfs:Class }
That is exactly what the RDFS level in Cuebee does (note that the concept of Class is within the dialect of RDFS).
Acknowledgements
Many thanks to everybody that contributed with ideas, requirements and implementation, especially, but not limited to the names cited below.
Maciej Janik, partner in project "Cuadro" (2005), for his initial implementation of query builder
Matt Eavenson, partner in project "Cuadro" (2005), for his Lucene+Ajax text autosuggestion code
Bobby McKnight, partner in project "TcruziKB" (2007), for his contributions with the Results Explorers.
Sena Arpinar, collaborator in grant proposal Microbial Genome Analysis System (2008)
Funding
This research has been funded in part at the Kno.e.sis Center by grants from AHA, NSF and NIH.
Building a Trypanosoma cruzi genome resource: Integrating diverse genomic data sets to facilitate basic research; from the American Heart Association, grant number AHA 0330338N. Principal Investigator: Jessica C. Kissinger
National Science Foundation under Award No. 071441 to Wright State University and No. IIS-0325464 to University of Georgia titled “SemDis: Discovering Complex Relationships in the Semantic Web. Principal Investigator: Amit Sheth, Co-PIs: I. Budak Arpinar, Krys Kochut, and John Miller.
Research Project (Collaborative RO1) Grant Number: 1R01HL087795-01A1
National Heart, Lung, and Blood Institute (NHLBI), National Institutes of Health (NIH). Principal Investigator: Dr. Amit Sheth Kno.e.sis Center, Wright State University
Any opinions, findings, conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the American Heart Association, National Science Foundation, National Institute of Health, University of Georgia, Wright State University or the university systems of Georgia and Ohio.
License
Cuebee (Query Builder and Results Explorer) is available for download with some rights reserved. This work is licensed under a Creative Commons Attribution-No Derivative Works 3.0 Unported License. We plan to change the license to a less restrictive one when the software matures from alpha stage.